|
SAP(Systems��Applications��and Products in Data Processing)��һ���ܱȽ�ǿ���ERPϵͳ��Ŀǰ����500ǿ����ҵ�����г���80����ʹ��SAP�����Ƕ��������SAP��˾�ṩ�Ĺ�����Эͬ����ƽ̨�����и�Ч�ʵĹ�����SAP�������ƷR/3�����ڷֲ�ʽ�ͻ���/�����������ļ��ɻ���ҵ����Ӧ����������Ҫ����ģ�����:���ۺͷ��������Ϲ����������ƻ�����������������ά�ޡ�������Դ����ҵ�������칫�Һ�ͨ�š���Ŀϵͳ���ʲ����������ơ������ơ�
SAP��������Դ����ģ��HR��Human Resource���Dz��ú���������Ա��������Ͱ���������ٴ���������ʽӦ�ó�ʽ������Ϊ��˾�ṩ������Դ�滮����������������� н�ʡ����á���ʱ����Ƹ����չ�ƻ������³ɱ��ȡ�Ȼ�����ڿ���HRģ��ȫ��ϵͳʱ����������ȫ��������ҵ�Ա�����ݴ�ԭ����һ��SAPϵͳ���뵽ͬһ��SAPϵͳ�����⣬Ŀǰ�����������Ա���õķ����ǣ�ͨ����Infotype¼����Ļ��ʾ�������ֶΣ����ֹ��������ֶ�����������ÿ������ͨ������������һInfotype�Ľṹ��������Щ����������������Լ�����ά��������Ĺ������Ϳ����ɱ��������ñ��IJ����������������Խ�������ͬ��Infotype�ṹͨ��ͬһ��������������Batchinput���������룩������ʵ�ָ�����Ա���ݵ���Ч�����ٵ��롣
һ�����ݵ���
��ȫ��������ҵ�Ա�����ݴ�ԭ����һ��SAPϵͳ���뵽ͬһ��SAPϵͳ��ʱ��һ����õķ����ǣ�ͨ����Infotype¼����Ļ��ʾ�������ֶΣ����ֹ��������ֶ�����������ÿ������ͨ������������һInfotype�Ľṹ����һ�ַ�����ͨ��¼����Ļ����ʾ�õ���¼�����ݵ��ֶΣ���ͨ���ֹ����ֶε������������Batchinput�������Ӧ�����ݵ��룬���ַ����������������Infotye���������Ч��ȱ���Dz����ô������IJ�������֮��Batchinput����ֻ��ͨ�����ϵĸ��ơ�ճ����������ɣ�������������ز��㡣�ڶ��ַ����Ƕ�ÿ������ͨ������������һInfotype�Ľṹ��û�к�Feature�������������ֶμ������ʺ��ִ���ȫ����ҵ�����磬���ڸ���������ͬһ��Infotype��¼�뻭���ϵ������ֶβ�����ͬ����ͼ1��ͼ2��ʾ���й�����������Ա���Ա��ֶ���Ͳ���ͬ��Ϊ�ˣ���ʹ�����Ϸ�����ͨ���ͱ��뽫ÿһ�����ҵ�ÿһ��Infotype����ͨ����ͬ��Batchinput������е��룬��ҪΪij�����˾����һ�����Ը������64�����ҵķֹ�˾��Ա��Ϣϵͳ����ÿ�����ҳ��õ�Infotype��Subtype��Լ32�֣�������Ա�ͱ������32*64=2048��Infotype���ݵĵ��빤�������ұ����д2048��Batchinput�������������ݵ��룬��Ȼ˵������ܻ��Ǵ�ͬС�죬�������Ը����������Լ����ڵ�ά��������Ĺ������Ϳ����ɱ���
 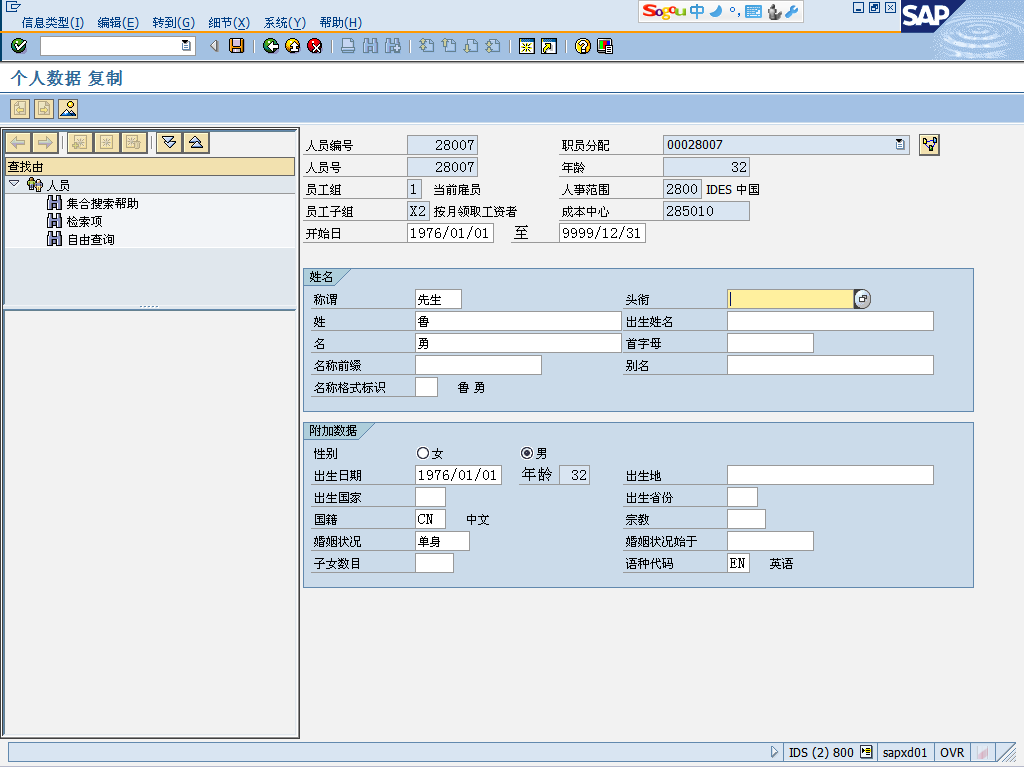
ͼ1 �й�ְԱ������Ϣ�����Infotype0002���� Infotype¼�뻭��
 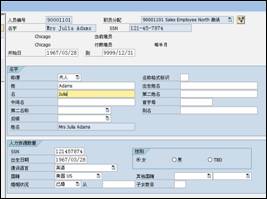
ͼ2 ����ְԱ������Ϣ�����Infotype0002���� Infotype¼�뻭��
��ˣ��ڿ���������̽��������������ͨ�õĽ���������������ж��ٸ����ң�������Infotype��ֻҪʹ�����ֽ���������Ͷ��ܰ�ÿ�����Ҳ�ͬ��Infotype�ṹ������ÿ���ֶ��Ƿ�Ϊ�����ֶΡ����������͡����ݳ��ȵȣ�������������Ա�Ϳ����ڵ����ṹ�Ļ����ϰ�����ͨ��Batchinputһ���Եء����ٵء���Ч�ص��룬Ҳ������Ҫ��ÿ�����ҵ�Infotype¼�뻭����нṹ��ȷ�ϡ�
����ͨ�÷���
1����������
�ڵ���Infotype�ṹǰ�����������������Щ������������Щ�����ֶ���������ʱ�ǿ���ͨ��Batchinput����¼��ġ���Щ�DZ����ֶΣ������ֶξ�������Batchinputʱ�����������ֵ������ʱ������ֶε�˵�����Ƿ���䡢���������Լ����ݳ��ȡ�
��ͼ3��ʾ��Ҫ���й�ְԱ��Infotype�ṹ���е�������Ҫ��ͼ3�����Infotype¼�뻭����֪����Щ�ֶ��ǿ��Ա�����ģ���Щ�ֶ��DZ�������ġ����硰ͷ�Ρ��ֶΣ����ֶ��������ֶΣ���ͷ�Ρ����Ǹ��ֶε�˵�����鿴���ֶ���������ͼ3���Ҳ࣬����֪�����ֶ�����P0002-TITEL���������Batchinput��ʱ������õ����ڷ�����������Ǿ��Ǹ��ݡ���Ļ���ݡ���ָ���ġ�������-MP000200���͡���Ļ��-2028�����ٴ�SAP�е�������ĺ���ȡ��������Ҫ���ֶ�������ȡ������Щ�ֶ��ö��������������γ�CSV�ļ�������ļ��������ݵ���Ļ��������ǵķ�������Ҫͨ����Ƶij���������ȡ����������������͡���Ļ�š���Ȼ���ٶ�ȡ���Ľṹ���мӹ������յõ������ṹ��CSV�ļ���
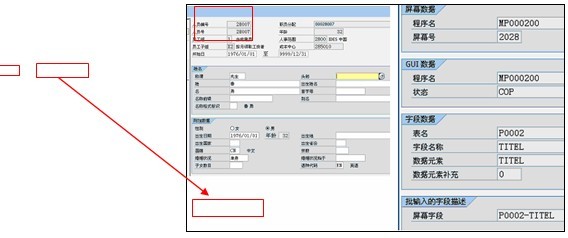
ͼ3 �й�ְԱ ��ͷ�Ρ��ֶεľ�����Ϣ����
2�������ѵ�
������������������ѵ����£���ζ���Feature�����ôӶ�������¼���������һ����������͵��������������Ӧ���ҵ�infotype�ṹ��ֻ�ܵ���infotype��ʾ���ֶΣ�����ʾ���ֶβ��ܵ�����
3. ���˼·

ͼ4 �����������ͼ
�����������Ľ�������������ѵ㣬��ͼ4�DZ��������������ͼ�����潫�Խ�������ľ��岽����в�����
(1)��ȡFeature������ʵ�ִ�¼���������һ����������Ϳɵ��������������Ӧ���ҵ�infotype�ṹ����¼����������Personnel Area(��������)�����ù��Ĺ��Ҵ��룬�����й���SAPϵͳ�еĹ��Ҵ�����CN�������Դ�����ZH�������Ҫ��ϵͳ��T500P��ȡ�����Ҵ���CN���ù��Ҵ���CN��Ϊ������T005��ȡ�����Դ���ZH��ȡ�����Դ�����ٸ��������Infotype��ϵͳ��T582Aȡ����Infotype��Ӧ��Screen Number���ٸ�������Infotype��ϵͳ��T777Dȡ����Ӧ��Module Pool��
����ȡ����Module Pool ��Screen Number��ϵͳ��T588Mȡ����Ӧ��Feature���룬��ȡ��������ȫ��ṹ����PME04�����Ժ�Screen Number�Լ�����һЩͨ�����ݣ���PME04��Ϊȫ�ֱ�������Include����RPUMKC00������ӳ���RE549D��ͨ��RE549D�����FUNCTION 'HR_FEATURE_BACKFIELD'����Feature�����Ӧ���ҵĸ�Infotype��VARKY����ͼ5��ʾ��������ȡ����T588M��������KEY��Module Pool��Screen Number��VARKY�����Ӷ�����ȷ��T588M���Ψһһ����¼��ȡ���ü�¼�������Ļ��ADYNR������Ļ���ƣ�DBILD�������ֶΡ�
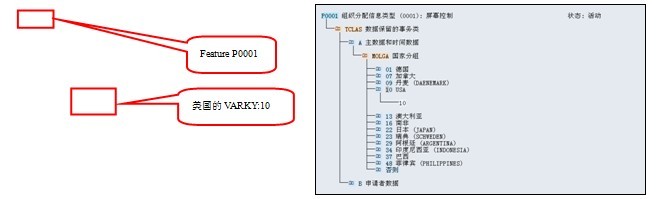
ͼ5 Feature P0001����
��ȡ������Module Pool �������Ļ�������Դ�����Ϊ����������FUNCTION 'IMPORT_DYNPRO'�Ϳ��Ե��������Ļ���ֶκ���Ӧ������˵��������������Infotype�ij����ṹ��
(2)����infotype��ʾ���ֶΣ�����ʾ�ֶβ�������
�����ǶԵ�������Ipfotype�ṹ����ȷ�Եĵ������������ֶε�������Ϣ�Ƿ��ʵ����е������Ե����ֶ��Ƿ������ڻ�������ʾ�����жϣ�������ʾ�ֶβ�Ҫ���������ɵ������ļ��
ȡ������Infotype�ṹ��ÿ���ֶ��а��������ڵı�����Ϊ������Ҫ�õ�����ֶε���Ӧ���Ե�ȷ˵����Ҫ����FUNCTION 'NAMETAB_GET'�������Դ��롢������Ϊ������������������Ӧ����˵����ȡ������
�ֶ��Ƿ���ʾ����Ϣ����Ļ��������ڣ��������Ҫ��ȡ�����������ṹ����ѭ����Ȼ���ж�ÿ���ֶζ�Ӧ����Ļ�������Ƿ�����ʾ��Ϣ���������Ѹ��ֶηŵ�����ļ��Ľṹ���֮�š�
�жϺ��Ƿ���ʾ���ø��ֶ���Ϊһ��keyȥ��ͨ��FUNCTION 'NAMETAB_GET'ȡ�������ڱ����Ѹ��ֶε���Ӧ˵��ȡ������
4���������
��1��ʵ�黷��
���������ABAP��̣������滷������ͨ����Windows XP Ӣ�İ棬SAP ECC6.0���ڴ�1GB��Ӳ��120GB��CPU 1.83GHz��
��2��ʵ�������Ҫ�������
����¼�뻭���������������ȡ�ù��Ҵ��루LAND1�������ҷ��飨MOLGA����Ȼ�����ȡ�õĹ��Ҵ��루LAND1��ȡ�����Դ��루SPRAS��������������ʾ��
* Get SPRAS From T005
SELECT SINGLE SPRAS
FROM T005
INTO I_WRK_SPRAS
WHERE LAND1 = I_WRK_LAND1.
����¼�뻭�������Infotype��ϵͳ��T582Aȡ���Ի�ģ�����ƣ�DNAME������һ��Ļ�ţ�EDYNR����
Ȼ�����¼�뻭�������Infotypeȡ��Module Pool��REPID��������������ʾ��
* GET HR: Infotype Module Pool from T777D
SELECT SINGLE REPID
FROM T777D
INTO I_WRK_REPID
WHERE INFTY = UP_INFTY.
��������ȡ�õ�Module Pool��REPID������һ��Ļ�ţ�EDYNR��ȡ��Feature��ZYKLS������Ļ���ƣ�DBILD������������ʾ��
* GET Feature for determining variable key from T588M
SELECT SINGLE ZYKLS DBILD
FROM T588M
INTO (I_WRK_ZYKLS�� I_WRK_DBILD)
WHERE REPNA = I_WRK_REPID AND
DYNNR = I_WRK_EDYNR AND
VARKY = SPACE.
��ȡ�õ��������õ��ṹPME04�У�Ȼ�����ñ�����RE549Dȡ�ñ����루VARKY��������������ʾ��
* Set structure
PME04-MOLGA = I_WRK_MOLGA.
PME04-TCLAS = I_CON_TCLAS.
PME04-ITBLD = I_CON_ITBLD.
PME04-DYNNR = I_WRK_EDYNR.
PME04-FCODE = I_CON_IOPER-INS.
* READ FEATURE
PME04-SUBTY = I_WRK_SUBTY.
PERFORM RE549D USING I_WRK_ZYKLS
I_CON_3
L_WRK_VARKY
L_WRK_RC.
�������ϲ���ȡ�õ�Module Pool��REPID������һ��Ļ�ţ�EDYNR���������루VARKY��ȡ�������Ļ��ADYNR������Ļ���ƣ�DBILD��������������ʾ��
SELECT SINGLE ADYNR DBILD
FROM T588M
INTO (CP_DYNUMB�� I_WRK_DBILD)
WHERE REPNA = UP_REPNA AND
DYNNR = UP_DYNNR AND
VARKY = UP_VARKY.
�������ϲ���ȡ�õ�Module Pool��REPID���� �����Ļ��ADYNR���������Դ��루SPRAS��ȡ���������Ļ�ϵ������ֶΡ�����������ʾ��
CALL FUNCTION 'IMPORT_DYNPRO'
EXPORTING
DYLANG = UP_DYLANG
DYNAME = UP_DYNAME
DYNUMB = UP_DYNUMB
TABLES
FTAB = I_TAB_FTAB
EXCEPTIONS
DYLANGUAGE_INVALID = 1
DYLANGUAGE_NOT_INST = 2
DYNAME_INVALID = 3
DYNPROLOAD_NOT_FOUND = 4.
�Ե����Ļ����ϵ������ֶν����Ƿ���ʾ���жϣ����ֶ���ʾ�ڻ�������ô��ȥȡ���ֶε�����˵�������������Լ����ȡ����ݱ�����ȡ����ʾ�ֶε�˵�����������ͺ��ֶγ��ȡ�����������ʾ��
CALL FUNCTION 'NAMETAB_GET' "#EC *
EXPORTING
LANGU = L_WRK_LANGU
ONLY = SPACE
TABNAME = L_WRK_TABNAME
TABLES
NAMETAB = I_TAB_DNTAB
EXCEPTIONS
INTERNAL_ERROR = 1
TABLE_HAS_NO_FIELDS = 2
TABLE_NOT_ACTIV = 3
NO_TEXTS_FOUND = 4
OTHERS = 5.
��3��ʵ����
ͨ��������������ε����У������ѳ���ȡ�õ��ֶΡ��ֶ�˵�����������͡��Ƿ���䡢�ֶγ�����֯������������������Ҫ�ĸ�����ͬInfotype�ṹ�������ļ��DCSV�ļ���
��4����������
�����������д�ij��������֮�����һ���Ե���64�����ҵij���Infotype��Subtype 32�ֽṹ���ڿ�������ʹ���л���˳ɹ���Ϊȫ����ҵ��ְԱ���ݵ������˺ܴ����⣬Ϊ�������̺ͺ���ά����Լ�˺ܴ�ɱ��������˿������ڣ�����˿ͻ���һ�º�����
�������DZ����ڳ��ڵ�����������ʹ��SAP�У����ݿ���HRģ��ȫ��ϵͳʱ���������������Ľ����������ͨ��������ʵ��֤ʵ�������ͳ������Ŀ����Ժ�ʵ���ԣ�Ϊ�����Ŀ����ͺ���ά����ʡ�˾�Ĺ������Ϳ����ɱ������⣬Ҫע����ϵͳ���ߺ�Feature�����ò�Ҫ����Ķ�������������һ��Ҫ��BASIS��ԱЭ�̺ã��Ų��ᵼ�²�������IJ�����
|



