|
网络蜘蛛即Web Spider,是一个很形象的名字。它把互联网比喻成一个蜘蛛网,而Spider就是在网上爬来爬去的蜘蛛。网络蜘蛛是通过网页的链接地址来寻找网页,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其他链接地址(在该程序中链接验证仅在href指定的链接上进行),然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。
Spider源文件压缩包中有一个说明性网页,其中把该程序称为:Pre-emptive Multithreading Web Spider,即抢先式多线程网络蜘蛛。抢先式多线程即基于线程的抢先式多任务处理,它的运行机制是操作系统在给各个线程分配CPU时间片时,通过其本身的调度机制来评价各个活动线程的优先级,优先执行优先级别高的活动线程,挂起优先级别低的活动线程;当活动线程优先级别相同时,系统调度程序则以轮转方式分配CPU时间片。在抢先式多任务处理中,只要系统调度程序确定有一个优先级别更高的线程准备运行,则系统立刻会将优先级别低的线程挂起(即使处于运行状态),而把CPU时间片分配给优先级别高的线程。
在Spider程序运行过程中,“多线程”主要体现在检查一个基于URL链接的Web页面时,如果要继续跟踪其链接页面,就会启动一个新的线程跟随每个新的URL链接,索引一个新的URL起点,同时把这个新的线程添加到线程列表中。“抢先式”则在于:程序的执行过程并不是有条理地完全按流程执行,中间会出现没有规律的跳转,比如在这个线程正在建立的过程中,就可能跳转到另外一个线程的运行过程里。这里就是一个线程优先级的问题。如上所述的运行机制,如果程序确定有一个优先级别更高的线程准备运行,则立刻会将优先级别低的线程挂起,而把时间片分配给优先级别高的线程。
从遍历的角度来看,该网络蜘蛛可以看作是广度优先遍历,因为它会先抓取起始网页链接的所有网页,然后对每个网页建立新的线程予以跟踪,继续抓取这些网页所链接的网页。
1.功能介绍
Spider工程文件运行界面如图1所示,其主要的功能体现在Tools菜单中。
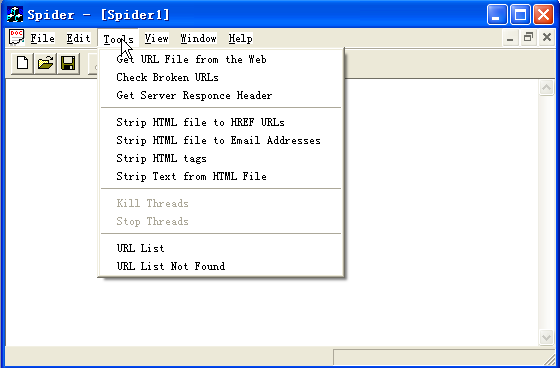
图1工程的Tools菜单
(1)点击Get URL File from the Web弹出对话框如图2所示。
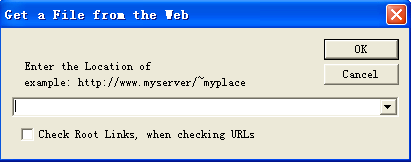
图2 “Get URL File from the Web”对话框
在弹出的对话框中输入一个Web地址,就可以得到这个页面的html源文件。
如果选中Check Root Links,则检查该网站所有链接的状态,否则只检查当前页面的链接状态。
(2)通过“File”―>“Open”打开一个html源文件,点击Strip HTML file to HREF URLs 可把网页的html源文件中href指定的链接提取出来,菜单中的其余选项不再赘述。
2.流程分析
Spider程序的核心功能是检查一个网站的所有链接状态,所以本文主要对实现这个功能所涉及到的数据结构以及流程进行了研究。
(1)提取href链接的流程
因为链接验证仅在href指定的链接上进行,所以首先要把这些链接提取出来。它的核心是两个方法:GetHref和FindHref。其中所涉及到的主要数据结构是用CStringList类所声明的Rlist和list实体对象。如下在CStringList类的定义中,对它的节点结构和几个重要的方法作了标注:
class CStringList : public CObject
{
protected:
struct CNode
{
CNode* pNext;
CNode* pPrev;
CString data;
}
public:
int GetCount() const;
POSITION AddHead(LPCTSTR newElement);
POSITION AddTail(LPCTSTR newElement);
POSITION AddHead(const CString& newElement);
POSITION AddTail(const CString& newElement);
void RemoveAll();
CString& GetAt(POSITION position);
CString GetAt(POSITION position) const;
POSITION Find(LPCTSTR searchValue, POSITION startAfter = NULL) const;
};
可以看出,页面的所有链接地址像链表一样存储起来,这样的结构方便进行动态操作,而且不会对空间造成很大的浪费。
(2)跟踪Web地址的流程
网络蜘蛛进入一个网站,一般会先访问一个特殊的文本文件robots.txt,这个文件一般放在网站服务器的根目录下,如果spider程序发现它,将放弃搜索。网站管理员也可以通过robots.txt来定义哪些目录网络蜘蛛不能访问,或者哪些目录对于某些特定的网络蜘蛛不能访问。例如有些网站的可执行文件目录和临时文件目录不希望被搜索引擎搜索到,那么网站管理员就可以把这些目录定义为拒绝访问目录。当然,robots.txt只是一个协议,如果网络蜘蛛的设计者不遵循这个协议,网站管理员也无法阻止网络蜘蛛对于某些页面的访问,但一般的网络蜘蛛都会遵循这些协议。
网络蜘蛛跟踪一个Web地址的总体流程如图3所示。

图3 跟踪Web地址的总体流程
在这个程序中,通过使用线程索引一个基于URL链接的web页面,而在运行的过程中不断启动新的线程跟随每个新的URL链接,索引新的URL起点。
其中线程的结构如下:
typedef struct tagThreadParams
{
HWND m_hwndNotifyProgress;
HWND m_hwndNotifyView;
CWinThread* m_pThread;
CString m_pszURL; //the name of the web
CString m_Contents;
CString m_strServerName; //the name of the Server
CString m_strObject;
CString m_checkURLName;
CString m_string;
DWORD m_dwServiceType;
DWORD m_threadID;
DWORD m_Status;
URLStatus m_pStatus;
INTERNET_PORT m_nPort;
int m_type;
BOOL m_RootLinks;
}
ThreadParams;
在创建每个CSpiderThread对象时,它的构造函数提供了ThreadProc函数以及将传送到ThreadProc函数的线程参数。
CSpiderThread* pThread;
pThread = NULL;
pThread = new CSpiderThread(CSpiderThread::ThreadFunc,pThreadParams);
// 创建一个新的CSpiderThread 对象;
CSpiderThread对象创建后,用CreatThread函数开始一个新的线程对象的执行。只有顺利完成这两个过程,才能把新线程添加到队列中去。
图4给出线程执行的流程。

图4 线程执行
其中分解URL是为了得到线程结构中的m_type值,当它的值为1时代表要进行检查链接状态的处理。因为本文重点是检查链接状态,所以流程图中没有画出case条件的其它情况。再有要说明的一点是,读取网页源文件是逐行读入的。因为它的流程并没有涉及到很多内容,所以这里没有给出。图5是检查所有链接状态的流程。
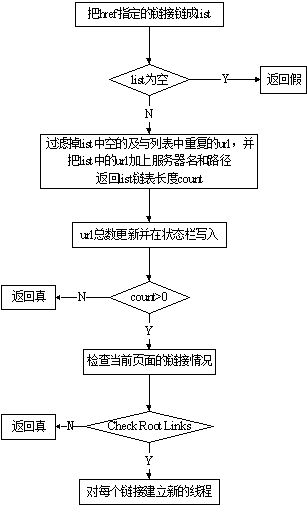
图5 检查链接状态
其中对每个链接建立新的线程的过程中,还要过滤掉和首页相同的页面,检查线程个数是否超过限定值。
本文程序代码在VC6.0环境下跟踪调试,并给出其中涉及到的重要结构和流程图,大家据此可以更好地理解MFC网络蜘蛛的实现。
|



