|
{
return nextMatch.Value; // 返回href
}
return null;
}
catch (Exception e)
{
throw e;
}
}
在getHref方法中使用了正则表达式从<a>中获得href。在<a>中正确的href属性格式有三种情况,这三种情况的主要区别是URL两边的符号,如单引号、双引号或没有符号。这三种情况如下所示:
情况1: <a href = "http://www.comprg.com.cn" > comprg</a>
情况2: <a href = 'http://www.comprg.com.cn' > comprg</a>
情况3: <a href = http://www.comprg.com.cn > comprg</a>
getHref方法中的p存储了用于过滤这三种情况的href,也就是说,使用正则表达式可以获得上述三种情况的href如下:
从情况1获得得的href:href = “http://www.comprg.com.cn”
从情况2获得得的href:href = ‘http://www.comprg.com.cn'
从情况3获得得的href:href = http://www.comprg.com.cn
在获得上述的href后,需要将URL提出来。这个功能由getURL完成,这个方法的实现代码如下:
// 从href中提取URL
private String getURL(string href)
{
try
{
if (href == null) return href;
int n = href.IndexOf('='); // 查找'='位置
String s = href.Substring(n + 1);
int begin = 0, end = 0;
string sign = "";
if (s.Contains("\"")) // 第一种情况
sign = "\"";
else if (s.Contains("'")) // 第二种情况
sign = "'";
else // 第三种情况
return getFullURL(s.Trim());
begin = s.IndexOf(sign);
end = s.LastIndexOf(sign);
return getFullURL(s.Substring(begin + 1, end - begin - 1).Trim());
}
catch (Exception e)
{
throw e;
}
}
在获得URL时有一点应该注意。有的URL使用的是相对路径,也就是没有“http://host”部分,但将URL保存时需要保存它们的完整路径。这就需要根据相对路径获得它们的完整路径。这个功能由getFullURL方法完成。这个方法的实现代码如下:
// 将相对路径变为绝对路径
private String getFullURL(string URL)
{
try
{
if (URL == null) return URL;
if (processPattern(URL)) return null; // 过滤不想下载的URL
// 如果URL前有http://或https://,为绝对路径,按原样返回
if (URL.ToLower().StartsWith("http://") || URL.ToLower().StartsWith("https://"))
return URL;
Uri parentUri = new Uri(parentURL);
string port = "";
if (!parentUri.IsDefaultPort)
port = ":" + parentUri.Port.ToString();
if (URL.StartsWith("/")) // URL以"/"开头,直接放在host后面
return parentUri.Scheme + "://" + parentUri.Host + port + URL;
else // URL不以"/"开头,放在URL的路径后面
{
string s = "";
s = parentUri.LocalPath.Substring(0, parentUri.LocalPath.LastIndexOf("/"));
return parentUri.Scheme + "://" + parentUri.Host + port + s + "/" + URL;
}
}
catch (Exception e)
{
throw e;
}
}
在ParseResource中还提供了一个功能就是通过正则表达式过滤不想下载的URL,这个功能将通过processPattern方法完成。实现代码如下:
// 如果返回true,表示URL符合pattern,否则,不符合模式
private bool processPattern(string URL)
{
foreach (string p in patterns)
{
if (Regex.IsMatch(URL, p, RegexOptions.IgnoreCase | RegexOptions.ExplicitCapture)
&& !p.Equals(""))
return true;
}
return false;
}
ParseResource类在分析HTML代码之前,先将HTML下载到本地的线程目录中,再通过FileStream打开并读取待分析的数据。ParseResource类其他的实现代码请读者参阅本文提供的源代码。
七、键树
在获取URL的过程中,难免重复获得一些URL。这些重复的URL将大大增加网络蜘蛛的下载时间,以及会导致其他的分析工具重复分析同一个HTML。因此,就需要对过滤出重复的URL,也就是说,要使网络蜘蛛下载的URL都是唯一的。达到这个目的的最简单的方法就是将已经下载过的URL保存到一个集合中,然后在下载新的URL之前,在这个集合中查找这个新的URL是否被下载过,如果下载过,就忽略这个URL。
这个功能从表面上看非常简单,但由于我们处理的是成千上万的URL,要是将这些URL简单地保存在类似List一样的集合中,不仅会占用大量的内存空间,而且当URL非常多时,如一百万。这时每下载一个URL,就要从这一百万的URL中查找这个待下载的URL是否存在。虽然可以使用某些查找算法(如折半查找)来处理,但当数据量非常大时,任何查找算法的效率都会大打折扣。因此,必须要设计一种新的存储结构来完成这个工作。这个新的数据存储结构需要具有两个特性:尽可能地减少存储URL所使用的内存。查找URL的速度尽可能地快(最好的可能是查找速度和URL的数量无关)。
下面先来完成第一个特性。一般一个URL都比较长,如平均每个URL有50个字符。如果有很多URL,每个URL占50个字符,一百万个URL就是会占用50M的存储空间。而我们保存URL的目的只有一个,就是查找某一个URL是否存在。因此,只需要将URL的Hashcode保存起来即可。由于Hashcode为Int类型,因此,Hashcode要比一个URL字符串使用更少的存储空间。
对于第二个特性,可以使用数据结构中的键树来解决。假设有一个数是4532。首先将其转换为字符串。然后每个键树节点有10个(0至9)。这样4532的存储结构如图2所示。
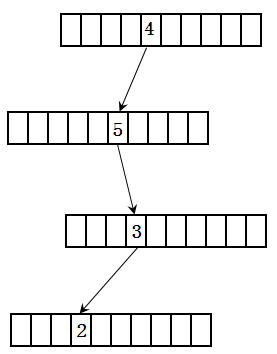
从上面的数据结构可以看出,查找一个整数只和这个整数的位数有关,和整数的数量无关。这个键树的实现代码如下:
class KeyTreeNode // 键树节点的结构
{
// 指向包含整数下一个的结点的指针
public KeyTreeNode[] pointers = new KeyTreeNode[10];
// 结束位标志,如果为true,表示当前结点为整数的最后一位
public bool[] endFlag = new bool[10];
}
class KeyTree
{
private KeyTreeNode rootNode = new KeyTreeNode(); // 根结点
// 向键树中添加一个无符号整数
public void add(uint n)
{
string s = n.ToString();
KeyTreeNode tempNode = rootNode;
int index = 0;
for (int i = 0; i < s.Length; i++)
{
index = int.Parse(s[i].ToString()); // 获得整数每一位的值
if (i == s.Length - 1) // 在整数的最后一位时,将结束位设为true
{
tempNode.endFlag[index] = true;
break;
}
if (tempNode.pointers[index] == null)
// 当下一个结点的指针为空时,新建立一个结点对象
tempNode.pointers[index] = new KeyTreeNode();
tempNode = tempNode.pointers[index];
}
}
// 判断一个整数是否存在
public bool exists(uint n)
{
string s = n.ToString();
KeyTreeNode tempNode = rootNode;
int index = 0;
for (int i = 0; i < s.Length; i++)
{
if (tempNode != null)
{
index = int.Parse(s[i].ToString());
// 当整数的最后一位的结束标志为true时,表示n存在
if((i == s.Length - 1)&& (tempNode.endFlag[index] == true))
return true;
else
tempNode = tempNode.pointers[index];
}
else
return false;
}
return false;
}
}
上面代码中的KeyTreeNode之所以要使用结束标志,而不根据指针是否为空判断某个整数的存在,是因为可能存在长度不相等的整数,如4321和432。如果只使用指针判断。保存4321后,432也会被认为存在。而如果用结束标志后,在值为2的节点的结束标志为false,因此,表明432并不存在。下面的URLFilter使用了上面的键树来处理URL。
// 用于将URL重新组合后再加到键树中
// 如http://www.comprg.com.cn和http://www.comprg.com.cn/是一样的
// 因此,它们的hashcode也要求一样
class URLFilter
{
public static KeyTree URLHashCode = new KeyTree();
private static object syncURLHashCode = new object();
private static string processURL(string URL) // 重新组合URL
{
try
{
Uri uri = new Uri(URL);
string s = uri.PathAndQuery;
if(s.Equals("/"))
s = "";
return uri.Host + s;
}
catch(Exception e)
{
throw e;
}
}
private static bool exists(string URL) // 判断URL是否存在
{
try
{
lock (syncURLHashCode)
{
URL = processURL(URL);
return URLHashCode.exists((uint)URL.GetHashCode());
}
}
catch (Exception e)
{
throw e;
}
}
public static bool isOK(string URL)
{
return !exists(URL);
}
// 加处理完的URL加到键树中
public static void addURL(string URL)
{
try
{
lock (syncURLHashCode)
{
URL = processURL(URL);
URLHashCode.add((uint)URL.GetHashCode());
}
}
catch (Exception e)
{
throw e;
}
}
}
八、其他部分
到现在为止,网络蜘蛛所有核心代码都已经完成了。下面让做一个界面来使下载过程可视化。界面如图3所示。
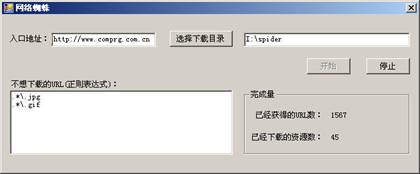
图3 程序运行界面
这个界面主要通过一个定时器每2秒钟获得个一次网络蜘蛛的下载状态。包括获得的URL数和已经下载的网络资源数。其中这些状态信息都保存在一个Common类的静态变量中。Common类和主界面的代码请读者参阅本文提供的源代码。
九、结语
至此,网络蜘蛛程序已经全部完成了。但在实际应用中,光靠一台机器下载整个的网络资源是远远不够的。这就需要通过多台机器联合下载。然而这就会给我们带来一个难题,就是这些机器需要对已经下载的URL进行同步。读者可以根据本文提供的例子,将其改成分布式的可多机同时下载的网络蜘蛛。这样网络蜘蛛的下载速度将会有一个质的飞跃。
|



