|
(3)创建多线程实例进行每个章节的下载。每个线程将从队列中取出一个地址,进行内容抓取,分析出正文,并将正文保存在一个临时目录下。
(4)主线程等待所有子线程结束。当所有子线程结束后,对文本进行合并,最后删除临时目录。
(5)程序结束。
2.目录结构
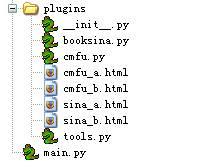
图1 目录结构
如图1所示整个程序由一个主程序(main.py)和plugins目录构成。plugins/tools.py是一个公共处理模块。plugins目录是整个程序的扩展部分,在这个工具中已经包含了对新浪读书频道和起点中文网站的支持,其中还包括有测试样例。plugins是按Python语言包的方式进行组织的,在目录下有一个__init__.py文件。booksina.py和cmfu.py分别是对应的两个网站的内容解析模块。
三、要点描述
下面将对某些处理要点进行详细分析和解释。
1.命令行参数处理
一个灵活的命令行程序一般都支持可选的命令行参数,本程序也不例外。比如:可以指定要使用的代理服务器,这对于在有防火墙的环境中使用会很方便。
parser = OptionParser(usage=get_usage())
parser.add_option('--proxy',
help='Proxy will be used. Default is using your env settings.')
parser.add_option('-u', '--proxyuser', help='Proxy user name.')
parser.add_option('-p', '--proxypassword', help='Proxy password.')
options, args = parser.parse_args(argv[1:])
这里使用了OptionParser模块对命令行参数进行定义和解析处理。它支持长格式参数和短格式参数。
if len(args) != 1:
parser.print_help()
sys.exit(0)
如果命令行后面没有参数,则显示帮助信息,程序结束。
|



