|
生成的XML数据格式如下所示:
<?xml version="1.0" encoding="utf-8" ?>
<China>
<Province name="北京市" value="110000" />
<Province name="天津市" value="120000" />
<Province name="河北省" value="130000">
<City name="石家庄市" value="130100">
<District name="市辖区" value="130101" />
…
<District name="鹿泉市" value="130185" />
</City>
…
<City name="廊坊市" value="131000">
<District name="市辖区" value="131001" />
…
<District name="三河市" value="131082" />
</City>
…
<Province name="香港特别行政区" value="810000" />
</China>
3 利用XML DOM访问XML数据
XML DOM定义了访问和操作XML文档的标准方法。文档对象模型将XML文档作为一个树形结构来访问,而其中的树叶被定义为节点。其规定整个文档是一个文档节点;每一个XML 标签是一个元素节点;包含在 XML 元素中的文本是文本节点;每一个 XML 属性是一个属性节点;注释属于注释节点。XML文档的树形结构如图1所示。
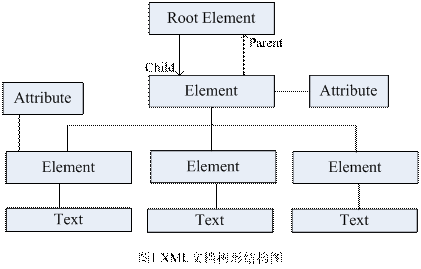
对于XML DOM 节点树来讲,可以通过它来访问所有节点,可以修改或删除它们的内容,也可以创建新的元素。本文重点论述的是如何访问节点并读取其中的内容。
首先是加载并解析XML文件。所有现代浏览器都内建了用于读取和操作XML的XML解析器,通过将XML读入内存,并把它转换为可被JScript访问的XML DOM对象。此处将介绍的是比较常用的微软的XML解析器加载XML的方式,其内建于Internet Explorer 5 及更高版本中。第一步是需要创建一个微软XML文档的ActiveXObject类型对象。启用并返回 Automation 对象的引用语法为:
newObjName = new ActiveXObject(servername.typename[, location])
其中newObjName为变量名,servername为提供该对象的应用程序的名称,typename为要创建的对象的类型或类,location为创建该对象的网络服务器的名称。
第二步是关闭异步加载,这样可确保在文档完整加载之前,解析器不会继续执行脚本。 最后是加载具体的XML文档。比如下面的代码就创建了名为xmlDoc的ActiveXObject类型对象,将异步加载方式关闭并且加载了名为exp1的XML文档。
|



